RAG架构升级
多步检索、重排序、跨文档推理及反向索引混合架构

高级RAG架构示意图
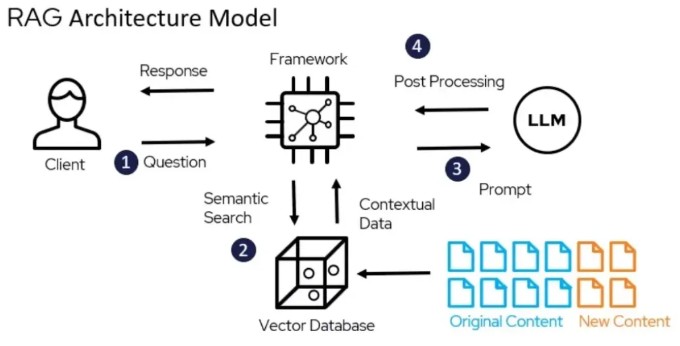
检索增强生成(Retrieval-Augmented Generation,RAG)技术正在经历革命性升级, 通过融合多步检索、重排序、跨文档推理及混合索引架构,为企业级应用提供更强大、更智能的知识处理能力。
传统RAG架构及其局限性
传统RAG架构概述
传统的RAG架构主要包含四个核心组件:文档处理、索引创建、检索器和生成器,通过以下流程工作:
文档处理
将各类格式的文档解析并分割成小块
索引创建
为文本块生成向量嵌入,建立向量索引
检索
根据用户查询检索相关文本块
生成
将检索到的内容与用户查询一起输入到大语言模型中生成回答
传统架构的局限性
传统RAG架构流程图
检索效率问题
单一检索策略难以应对复杂查询,容易漏掉重要信息
检索质量不稳定
向量检索高度依赖嵌入模型质量,对同义表述的敏感度不足
缺乏跨文档分析能力
无法有效整合多个文档中的信息进行推理
检索策略固定
无法根据查询复杂度动态调整检索方式
上下文窗口限制
传统RAG难以处理大量检索结果,容易丢失重要信息
RAG架构升级的关键技术
多步检索技术
多步检索通过迭代式查询过程逐步获取和整合信息,解决复杂问题的深度检索需求。
核心流程
- 查询分解:将复杂查询分解为多个简单子查询
- 迭代检索:基于初始检索结果生成新的查询,进行第二轮检索
- 上下文累积:随着检索轮次增加,不断积累和精炼上下文信息
- 条件终止:当满足一定条件(如信息充分或轮次达到上限)时结束检索
技术优势
- 处理复杂查询:能够应对多阶段推理问题
- 信息深度挖掘:通过追踪引用、关联信息等方式获取更全面的背景
- 减少幻觉:每一步检索都以实际数据为基础,降低生成虚假信息的可能性
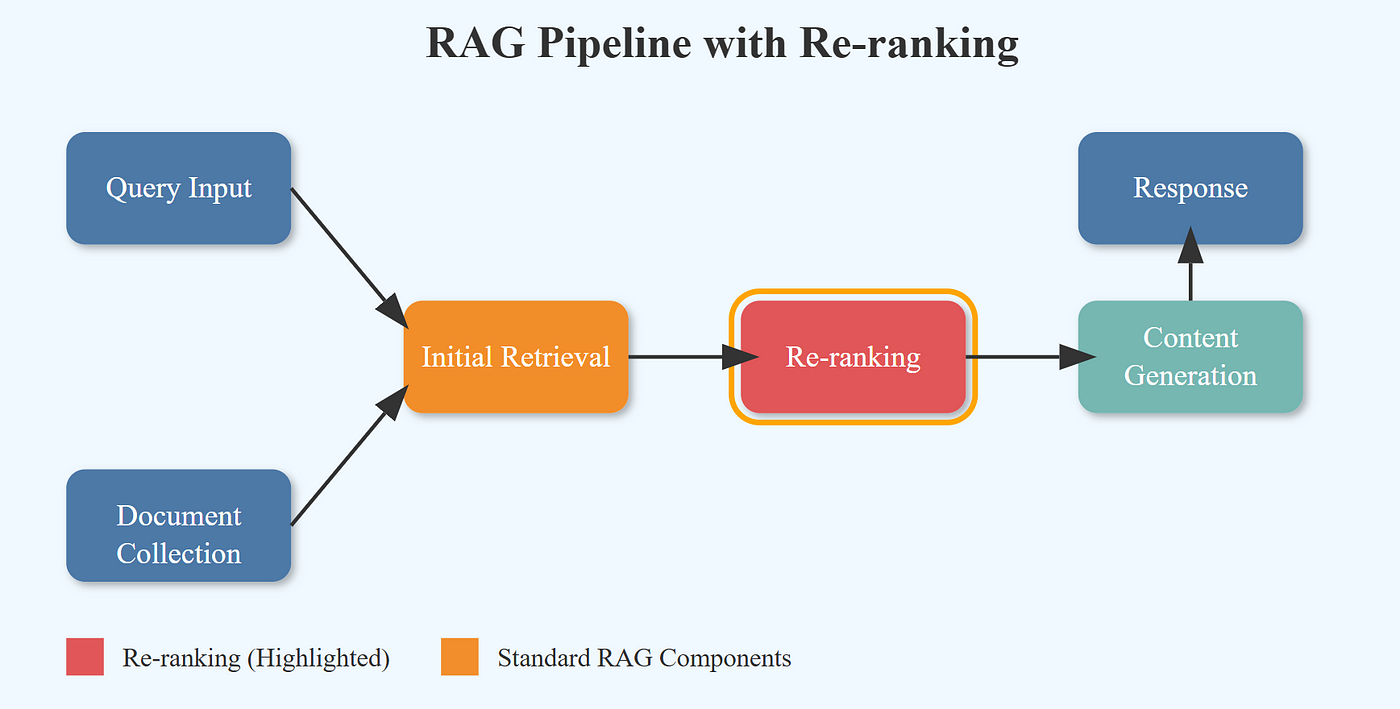
重排序技术
重排序技术通过更精确的相关性评估优化检索结果的质量和顺序,确保最相关内容优先呈现。

重排序技术原理
重排序通常采用两阶段检索策略:
- 第一阶段:使用高效的向量检索方法快速获取大量候选文档(通常为20-100个)
- 第二阶段:使用更精确但计算成本更高的模型(如交叉编码器)重新评估候选文档与查询的相关性,选出最相关的几个文档
主流重排序实现方法
- 基于语义的重排序:使用预训练的交叉编码器模型,如BGE Reranker、BAAI Reranker等
- 基于规则的重排序:根据时间顺序、来源可靠性等元数据进行重排
- 混合重排序:结合多种信号源的综合评分系统
- 多模型重排序:使用多个专业模型进行评分,然后集成结果
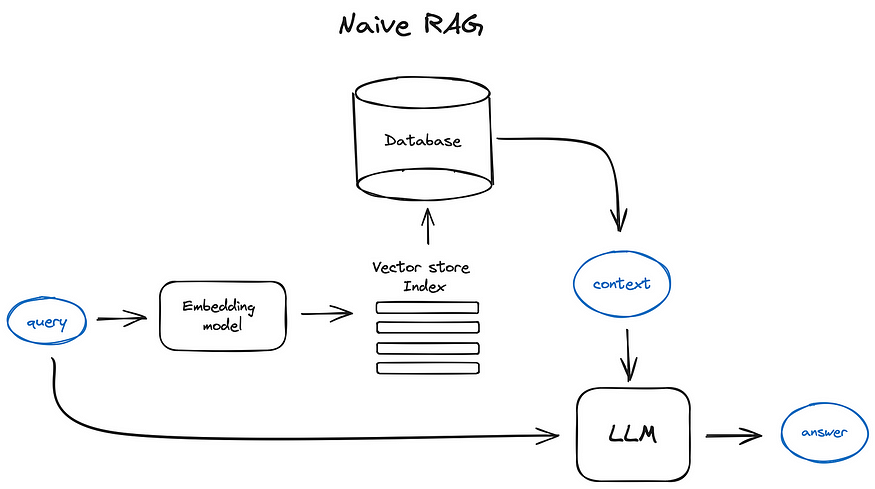
跨文档推理能力
跨文档推理解决了信息孤岛问题,能够从多个文档中提取、整合和推理信息,构建全面知识视图。
实现方法
- 图结构表示:使用知识图谱将不同文档中的实体和关系连接起来
- 多文档注意力:设计特殊的注意力机制,允许模型在处理不同文档时共享信息
- 信息融合层:引入专门的神经网络层,用于整合来自不同文档的相关信息
- 递归摘要树:构建层次化的文档摘要结构,便于跨层次、跨文档信息提取
应用场景
整合多篇学术论文的观点和发现
结合法律法规、案例判决和专家意见
从不同来源比对和验证信息的准确性
解答需要多个信息源综合的问题
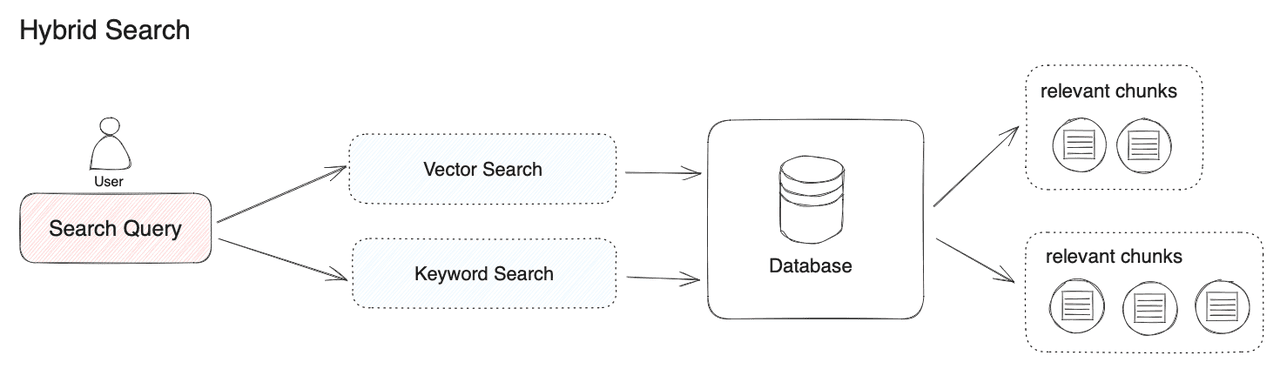
反向索引混合架构
结合传统倒排索引和向量索引的优势,创建更全面、更鲁棒的检索系统,平衡语义理解和精确匹配。
核心组件
倒排索引层
基于关键词的传统索引,用于快速精确匹配
向量索引层
基于语义的相似度匹配
混合检索引擎
整合两种索引结果的核心组件
动态权重调整
根据查询特性自动调整两种检索方式的权重
技术优势
- 语义理解与精确匹配并重:既能捕捉同义词、近义词等语义变化,又能精确匹配关键术语
- 抗噪声能力增强:减少了单一检索方法的偏差和局限性
- 适应性更强:能够自动适应不同类型的查询需求
- 召回率与精确率平衡:提高整体检索质量
企业级自适应RAG系统
企业级自适应RAG系统整合了先进技术,并引入了自适应机制,能够根据查询特性、数据特点和业务需求动态调整系统行为。
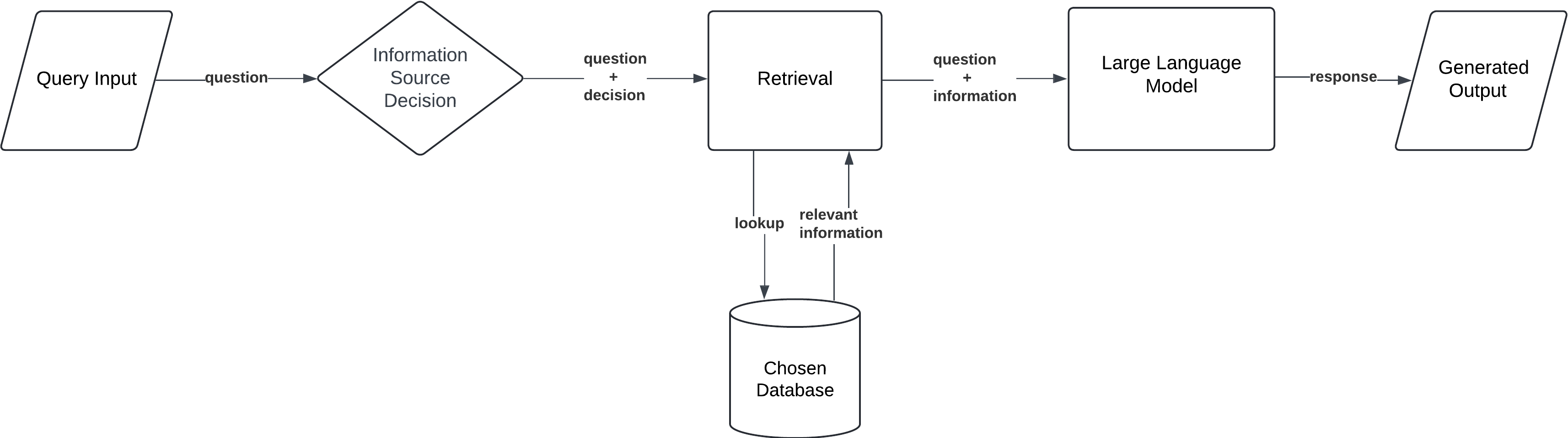
企业级自适应RAG系统架构图
自适应技术原理
自适应RAG系统的核心是能够实时评估查询复杂度并选择最佳检索策略
-
查询分析器
使用轻量级分类器评估查询复杂性和类型
-
策略选择器
根据查询分析结果动态选择无检索、单步检索或多步检索策略
-
上下文优化器
根据检索结果质量动态调整上下文窗口大小
-
反馈学习机制
通过用户反馈不断优化系统决策
企业级应用场景
智能客服与知识管理
- 自动回答从简单到复杂的客户查询
- 根据问题复杂度自动升级或调整回答深度
法律合规与风险管理
- 分析合同和法规文件
- 跨文档整合相关法律条款和先例
研发与创新支持
- 整合专利文献、研究报告和技术文档
- 提供多角度技术综述和发展趋势分析
财务和投资分析
- 整合季度报告、市场数据和分析师观点
- 生成多维度的投资决策支持资料
实现方法与挑战
实现路径
- 基础设施准备:构建支持混合索引的存储系统
- 模型选择与训练:选择或微调嵌入模型、训练查询分类器
- 流程编排:实现多步检索、重排序等高级功能的工作流
- 监控与优化系统:建立性能指标和反馈机制
- 安全与合规保障:确保数据隐私和访问控制
面临的挑战
计算资源需求增加
系统复杂度提升
评估标准不统一
跨源数据一致性
实时性要求
RAG架构技术比较
| 技术特性 | 传统RAG | 多步检索 | 重排序增强 | 跨文档推理 | 混合索引 | 自适应RAG |
|---|---|---|---|---|---|---|
| 查询复杂度处理 | 低 | 高 | 中 | 高 | 中 | 高 |
| 信息整合能力 | 低 | 中 | 中 | 高 | 中 | 高 |
| 检索精确度 | 中 | 中 | 高 | 中 | 高 | 高 |
| 计算资源需求 | 低 | 高 | 中 | 高 | 中 | 高 |
| 抗噪声能力 | 低 | 中 | 高 | 中 | 高 | 高 |
| 实施复杂度 | 低 | 中 | 中 | 高 | 中 | 高 |
表格说明:绿色表示性能高/优秀,黄色表示中等,红色表示较低/较差
未来发展趋势
RAG技术正处于快速发展阶段,未来将呈现以下趋势:
多模态RAG
整合文本、图像、音频和视频等多种模态的信息,提供更全面的知识理解和生成能力。
自主学习RAG
系统能够从交互中学习并优化检索策略,不断改进检索质量和响应准确性。
领域特化RAG
针对特定行业和应用场景定制的专业RAG系统,如医疗、金融、法律等垂直领域。
小型化RAG
高效率、低资源消耗的轻量级RAG解决方案,适用于边缘设备和资源受限环境。
分布式协作RAG
多智能体协作的复杂RAG架构,通过协作实现更强大的信息检索和推理能力。
隐私保护RAG
在保护数据隐私的前提下进行检索和生成,结合联邦学习和加密技术的新一代RAG系统。
总结
RAG技术通过多步检索、重排序、跨文档推理及反向索引混合架构等关键升级,已经发展成为连接大语言模型与企业知识库的强大桥梁。企业级自适应RAG系统通过整合这些先进技术,并引入动态调整机制,能够根据任务需求智能选择最佳策略,显著提升信息检索和生成质量。
尽管在实施过程中仍面临计算资源、系统复杂度等方面的挑战,但随着技术不断成熟和优化,RAG架构将在企业智能化转型中发挥越来越重要的作用。对于希望利用大语言模型增强知识管理和决策支持能力的企业而言,了解并应用这些先进RAG技术将成为核心竞争力的重要组成部分。
参考资料
-
Uğur Özker. (2024). Advanced RAG Architecture. Medium
-
Gaurav Nigam. (2024). A Complete Guide to Implementing Hybrid RAG. Medium
-
Microsoft Learn. (2025). Build Advanced Retrieval-Augmented Generation Systems. Microsoft
-
Humanloop. (2025). 8 Retrieval Augmented Generation (RAG) Architectures You Should Know. Humanloop
-
NVIDIA Developer. (2024). Enhancing RAG Pipelines with Re-Ranking. NVIDIA Technical Blog